
Lektion V
Funktion und Aufbau von Archivsystemen: Teil II
Heute geht’s weiter mit Archivsystemen! Wir beschäftigen uns wieder mit ArchivesSpace. Bei mir hat sich die kurze Repetition aus dem ersten Semester aus dem Einführungsmodul zu Archivwissenschaften wirklich gelohnt - ich hatte auf jeden Fall heute das Gefühl, etwas besser durchzublicken, was da genau läuft. Archivprozesse sind mir aber immer noch ziemlich fremd.
Import und Export
Ähnlich wie auch schon bei den Bibliothekssystemen machen wir hier eine Import & Export-Übung. Und zwar sollen fixfertige EAD-Daten heruntergeladen und in ArchivesSpace importiert werden. Meine Gruppe stand da peinlicherweise sehr lange auf der Leitung, denn wir konnten den Import nicht fertig durchführen - obwohl die Ausgabe behauptete, es hätte geklappt, fanden wir keine neuen Einträge. Dank Hilfe des Dozenten fanden wir dann heraus, dass es wirklich sinnvoll gewesen wäre, den Datentyp für den Import nicht auf MARC, sondern auf EAD zu stellen. Also unbedingt wie im Bild unten gezeigt das Datenformat ändern! So hat es dann geklappt. Es ist aber schade, dass ArchivesSpace keine automatische Prüfung macht, ob das Format stimmt.
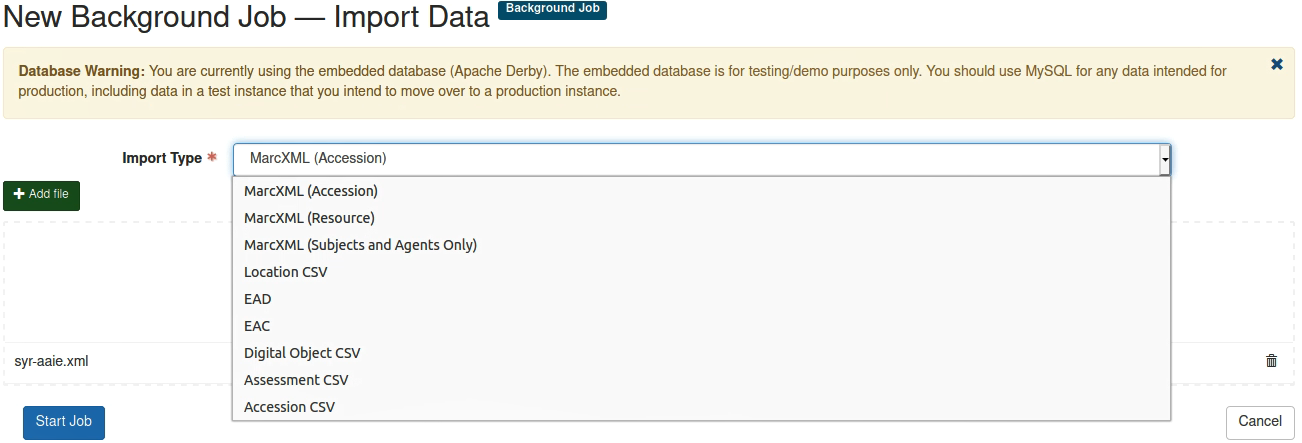
Als Quintessenz konnten wir festhalten, dass EAD zwar das beste Austauschformat ist, die Möglichkeiten aber auch begrenzt sind. Import und Export funktionieren nie verlustfrei und eine saubere XML-Datei ist eine Illusion…
(UPDATE nach einem Kommentar in der 8. Sitzung: Diese Aussage ist zu relativieren. XML-Daten können mit einem Datenformat-Schema auf die Form geprüft werden, bspw. mit OpenRefine (s. Lektion 7 und Lektion 8. Und es ist auch durchaus möglich, verlustfrei zu konvertieren - vorausgesetzt, das Zielformat hat mehr Möglichkeiten als das Ausgangsformat, beispielsweise DC zu MARC21.)
Marktüberblick Archivsysteme
Die im Kurs kennengelernte Software ArchivesSpace ist v.a. in den USA weit verbreitet. Eine Alternative, die benfalls Open-Source ist, wäre Access to Memory oder kurz AtOM. Diese Software wurde uns von Karin freundlicherweise spontan vorgestellt. In der Schweiz werden v.a. scope-Archiv und CMISTAR (wird z.B. an der ETH benutzt) verwendet. Da der Online-Zugang zu digitalen Daten immer wichtiger wird, wird oft Zusatzsoftware für Online-Archiv-Portale eingesetzt - wie z.B. e-Pics oder e-rara.
Archivsysteme vs. Bibliothekssysteme
Archive und Bibliotheken unterscheiden sich in ihrer Nutzungsform stark. Deshalb ist es kaum verwunderlich, dass die jeweiligen Systeme auch anders sind.
In Bibliotheken sind auf die Nutzer’innen und auch die Medien ausgerichtet. Die Software ist dementsprechend so gestaltet, dass die zentralen Ausleihprozesse möglichst einfach und speditiv ablaufen. Das Medium steht dabei im Zentrum. Meistens handelt es sich bei den Medien auch nicht um wertvolle Unikate, sondern Massenmedien, die ohne grösseren Aufwand ersetzt werden können, wenn mal wieder jemand versehentlich einen Kaffee darübergeleert hat. Der in Bibliotheken meistverwendete Metadatenstandard ist MARC21, welcher aber vermutlich bald von BIBFRAME abgelöst werden wird, da BIBFRAME linked data besser unterstützt.
In Archiven ist es etwas anders. Dort sind meistens weniger Massenmedien im Bestand, dafür viele Unikate, welche unter Umständen auch einen gewissen Wert haben. Dieser Bestand wird deshalb auch meist nicht ausgeliehen, sondern auf Anfrage vor Ort eingesehen. Die Software ist auch nicht medienzentriert wie in Bibliotheken, sondern orientiert sich stark an den analogen Findmitteln und dem Provenienzprinzip. Der Metadatenstandard ist ISAD(G) und auch das Format EAD wird häufig verwendet. Aber ähnlich wie in Bibliotheken ist auch hier der Nachfolger RiC schon bekannt.
Repository-Software für Publikationen und Forschungsdaten
Nachdem wir mit den Archivsystemen abgeschlossen haben, schauen wir uns Repository-Software an. Auf Deutsch übersetzt ist ein Repository eine Art Lager oder Depot. Repository-Software wird dementsprechend verwendet, um Daten in einem digitalen Verzeichnis zu speichern und zu verwalten. Dabei kann es sich um Software, Publikationen, Datenmodelle oder ähnliches handeln. Bevor wir uns mit DSpace eine Repository-Software anschauen, müssen aber noch einige Begrifflichkeiten geklärt werden.
Ein paar Begrifflichkeiten
Es gibt ja bekanntermassen viele “open”-Begriffe, wie z.B. das in diesem Blog schon oft erwähnte Open-Source, womit der offene Zugang zum Quellcode und damit auch zur Software gemeint ist. Bei Repositories sind die Begriffe Open Access, Open Data und Forschungsinformationen zu unterscheiden.
Der Begriff Open Access umfasst eigentlich eine ganze Bewegung, ist in unserem Kontext aber vor allem mit Publikationen in Verbindung zu setzen. Dabei werden die publizierten Erkenntnisse von Forschenden frei zur Verfügung gestellt, um den Zugang zu aktuellem Wissen zu sichern und das kollektive Wissen zu stärken. In der Schweiz sollen bis 2024 sollen alle mit öffentlichen Geldern finanzierten wissenschaftlichen Publikationen im Internet frei und kostenlos zugänglich sein.
Open Data hängt mit Forschungsdaten zusammen. Da werden also Primärdaten, welche während dem Forschungsprozess enstanden sind, zur Verfügung gestellt. Diese Daten können von allen und zu jedem Zweck verwendet, weiterverbeitet und genutzt werden. Eingeschränkt ist die Nutzung nur dadurch, dass meistens Klauseln vorhanden sind, welche beispielsweise die Nennung des Urhebers oder die Zusicherung des Weiterverbreitens des Wissens umfassen. Die Idee von Open Data ist darauf zurückzuführen, dass frei nutzbare Daten Transparenz und Zusammenarbeit fördern.
Forschungsinformationen bezeichnen Daten zu Forschenden, Projekten, Patenten, Finanzierungen, usw. Diese sind z.B. wichtig, um die Ratings von Universitäten zu erstellen, da diese darauf basieren, wie viel effektiv an der Uni geforscht wird, quasi im Sinne einer Forschungsberichterstattung. Es wird versucht, die Wissenschaft zu empirisieren und zu beobachten. Ziel ist es, beobachten zu können, was wie von wem zurzeit erforscht wird und wie es finanziert wird. Um das nachvollziehbar zu machen, werden an Universitäten meist Forschungsinformationssysteme verwendet, welche diese Daten zusammenführen können. Dabei ist es dann u.a. möglich, zu visualisieren, wer mit wem an welchen Projekten gearbeitet hat und wie gut die Forschenden vernetzt sind.
DSpace
DSpace ist eine freie Software, welche für Publikationen und Forschungsdaten geeignet ist. Digitale Ressourcen können damit erfasst, gespeichert und weiterverbreitet werden. Dabei ist DSpace an das aus dem Archivkontext bekannten OAIS-Referenzmodell für die digitale Langzeitarchivierung angelehnt, um die Langzeitverfügbarkeit digitaler Ressourcen zu sichern. DSpace stellt auch eine Erweiterung für Forschungsinformationen, DSpace-CRIS, zur Verfügung - CRIS steht dabei für current research information system. Der verwendete Metadatenstandard ist meistens Qualified Dublin Core, DSpace kann aber auch mit DataCite genutzt werden. Momentan befindet sich DSpace aber in einer kompletten “Umkrempelungsphase”. DSpace 6 ist die zuletzt veröffentlichte Version, Version 7 ist in der Beta-Phase und sollte ursprünglich 2020 veröffentlicht werden. In Version 7 werden neue Technologien eingesetzt (inkl. vorbildliche RESTAPI-Schnittstelle) und die Benutzeroberfläche ist umgemodelt. Im Kurs verwenden wir aber noch Version 6.
Für einmal war es nicht notwendig, etwas auf der virtuellen Maschine zu installieren. Stattdessen konnten wir für die kurze Übung (Community und Collection erstellen) die bereitsgestellte, webbasierte Demoversion verwenden. Diese ist öffentlich, was bei uns im Kurs leider das Administratoren-Konto ruiniert hat. Da aber die gesamten Testdaten immer am Samstag gelöscht werden, werden wir sicherlich in der nächsten Einheit noch mehr Funktionen kennen lernen können.



