
Lektion IX
Suchmaschinen und Discovery-Systeme: Teil II
Heute geht’s weiter mit Suchmaschinen und Discovery-Systemen, in unserem Fall also mit VuFind. Wir sind schon fast am Ende des Kurses angelangt und jetzt brauchen wir alle noch ein bisschen Durchhaltevermögen, damit wir auch den Hilfe-das-Semester-ist-bald-fertig-Workload meistern. In diesem Sinne - los geht’s mit dem, was wir in dieser Lektion gelernt haben!
Solr
Solr ist uns nach fast einem ganzen Semester Bibliotheks- und Archivinformatik wohl allen ein Begriff. Bisher wurde Solr aber nur am Rande erwähnt. Heute folgt eine Schnellbleiche dazu.
Solr ist eine open-source Suchmaschine, die in verschiedenen Anwendungsbereichen weit verbreitet ist und mittlerweile als Industriestandard gilt. Sie dient z.B. beim Discoverysystem VuFind als Suchmaschinen-Basis, wird aber auch von kommerziellen Produkten von Anbietern wie ExLibris verwendet.
Solr selbst hat nicht wirklich eine Suchoberfläche. Die gibt es entweder integriert in die Adminoberfläche oder als Demo, die ist aber völlig ungestaltet und wirklich nur zu Testzwecken gedacht. Moderne Usability-Anforderungen werden hier wohl nicht erfüllt.
Aber wie funktioniert Solr denn?
Solr sucht mittels Volltextsuche. Damit die Dokumente in einer Datenbank per Volltext durchsuchbar sind, sind mehrere Schritte nötig. Zuerst werden alle Dokumente indexiert, also in ein maschinell lesbares Format konvertiert. Dann folgt die Suchanfrage des Nutzers, welche durch die lexikalische Suche von Solr nicht 1:1 übernommen wird, sondern z.B. auf Grundformen reduziert wird. Diese Suchanfrage wird in einem nächsten Schritt namens Mapping auf die in der Datenbank gelagerten Dokumente gemappt und so nach Treffern gesucht. Zum Schluss folgt dann noch das Ranking, das nach Relevanz passiert - dazu später noch etwas mehr.
Es empfiehlt sich bei Solr, vor dem Datenimport in einem Schema festzulegen, welche Datentypen und Felder überhaupt gewünscht sind. Es gibt zwar die Möglichkeit, ohne Schema (schemaless) zu importieren, da fehlt dann aber die direkte Kontrolle, wo die Daten dann landen. Wichtig ist dann auch, welche Datentypen diese Daten beinhalten (z.B. Tabellen, Text, Nummern, Geokoordinaten, etc.). Das wäre dann schon wichtig, dass die jeweiligen Daten ins entsprechende Feld ankommen, damit z.B. Geokoordinaten suchbar sind oder es sich nach Zeiträumen suchen lässt. Wenn man nur Text importiert, geht das natürlich nicht. Deshalb macht es wirklich Sinn, mit dem Schema zu arbeiten.
Suchindex vs. Datenbank
Bei einem Suchindex wie z.B. Solr oder einer Datenbank wie z.B. MySQL handelt es sich in beiden Fällen um Systeme, in dem Daten gespeichert und gezielt wieder rausgeholt werden. Aber die beiden Systeme haben unterschiedliche Schwerpunkte.
So ist die Datenstruktur bei Suchindexen vergleichsweise eher flach. Jedes Objekt, das ich indexiere, ist genau ein Dokument mit verschiedenen Eigenschaften und Metadaten, aber es hat keine Beziehung zu anderen Objekten und steht alleine. Bei relationalen Datenbanken ist das - wie der Name schon sagt - anders. Hier gibt es Relationen und Beziehungen zwischen Objekten, was die Daten insgesamt viel strukturierter macht.
Auch die Datenabfrage selbst läuft anders ab. Wie bereits erwähnt funktioniert Solr mit einer lexikalischen Suche. Der Suchbegriff selbst hat also Grammatik, während dem Suchprozess wird dieser aber auf seine Grundform reduziert und nach dieser Grundform wird dann auch gesucht. Bei Datenbanken werden via SQL-Abfragen bestimmte Datensätze abgefragt. Aber anders als bei der lexikalischen Suche vergleicht die Datenbank ihre Daten nur 1:1 mit dem Suchbegriff.
Ein Suchindex hat weiter keine Kontrolle darüber, ob die darin enthaltenen Daten korrekt sind. Daten persistent zu sichern ist da nicht gut möglich, man speichert sie nur flüchtig. Bei einer Datenbank ist das anders. Die internen Datenbankregeln garantieren, dass der Datensatz auch im Falle eines Absturzes immer noch konsistent ist. In so einem Fall bleibt die Konsistenz der übrigen Datensätze erhalten, einfach ist derjenige, an dem man gerade gearbeitet hat, ist nach einem Absturz eventuell nicht mehr vorhanden.
Experimentieren mit VuFind
Nachdem wir letzte Woche VuFind bereits erfolgreich installiert und konfiguriert haben, können wir uns heute direkt mit den Übungen starten.
Suchen mit VuFind vs. Solr
In dieser Übung soll die Suchoberfläche von VuFind direkt mit der Suche via Solr verglichen werden.
Dazu brauchen wir die Beispieldaten, die wir letzte Woche bereits eingespielt haben. Bei VuFind wie auch bei Solr wurde nach dem Begriff psychologygesucht. Bei VuFind kam dieses Resultat zurück:
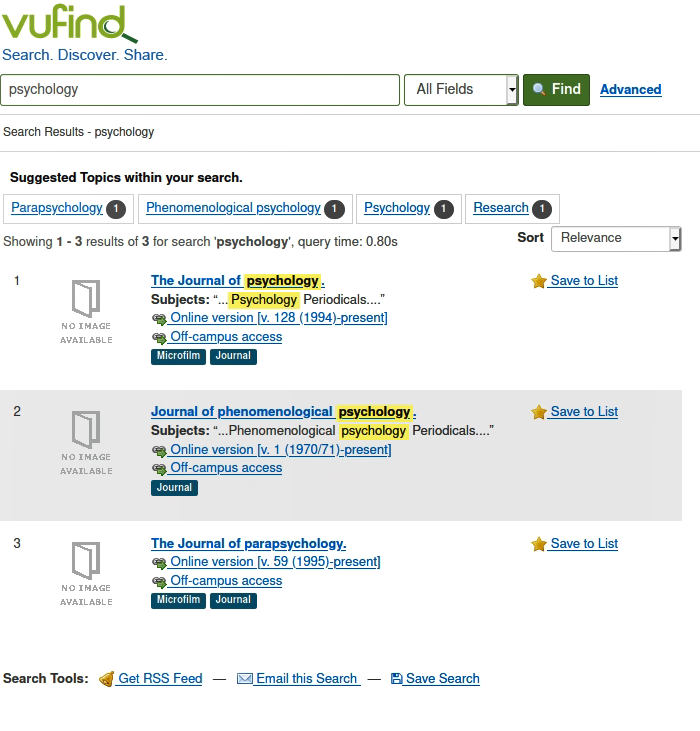
Bei Solr kamen die gleichen drei Resultate in der gleichen Reihenfolge raus. Hier natürlich ohne jede grafische Oberfläche, sondern einfach als JSON(?)-Daten.
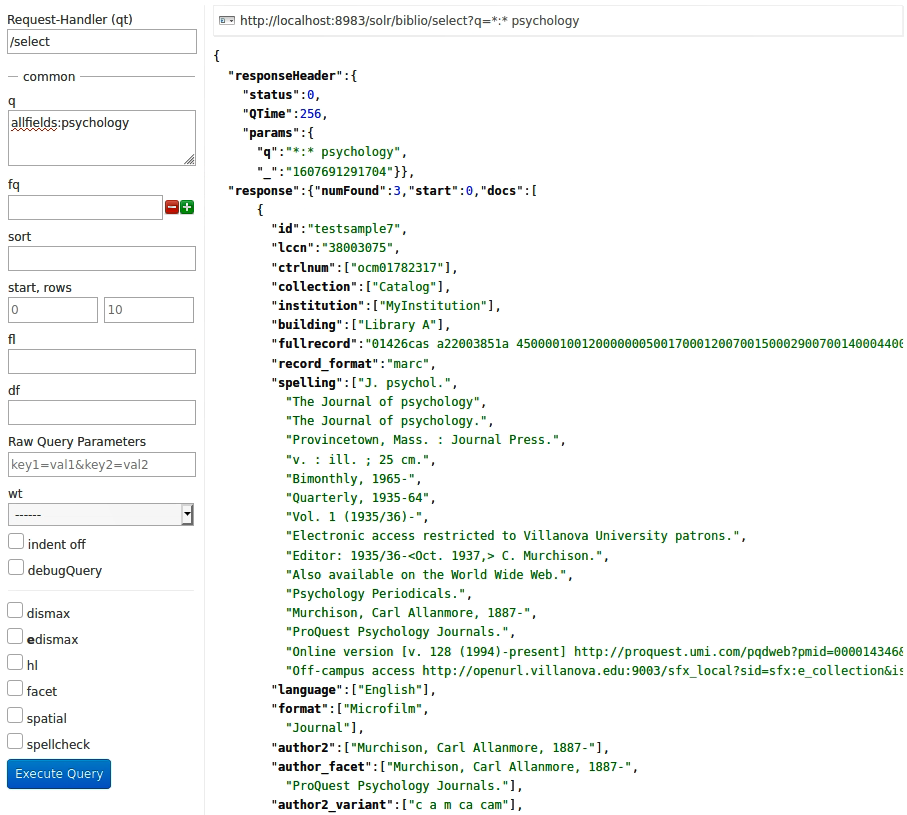
Das die beiden Suchresultate in der gleichen Reihenfolge ausgegeben werden, ist wohl v.a. auf die doch eher kleine Anzahl an Datensätzen in unserer Testdatenbank zurückzuführen. Ich nehme an, dass bei grösseren Datenmengen das Suchresultat doch etwas anders aussehen würde. Denn ein Blick auf die Logdatei gibt Aufschluss darüber, wie genau gesucht wurde.
Hier ein Blick auf die Solr-Abfrage:

Diese ist sehr kurz und knackig, was v.a. darauf zurückzuführen ist, dass ich nur im Feld q mit dem Begriff psychologygesucht habe. Solr kann natürlich eigentlich viel mehr, aber alle diese Einstellungen habe ich nicht vorgenommen. Solr macht hier also kein Ranking oder dergleichen.
Zum Vergleich dazu die Logdatei der Abfrage bei der VuFind-Suchoberfläche:
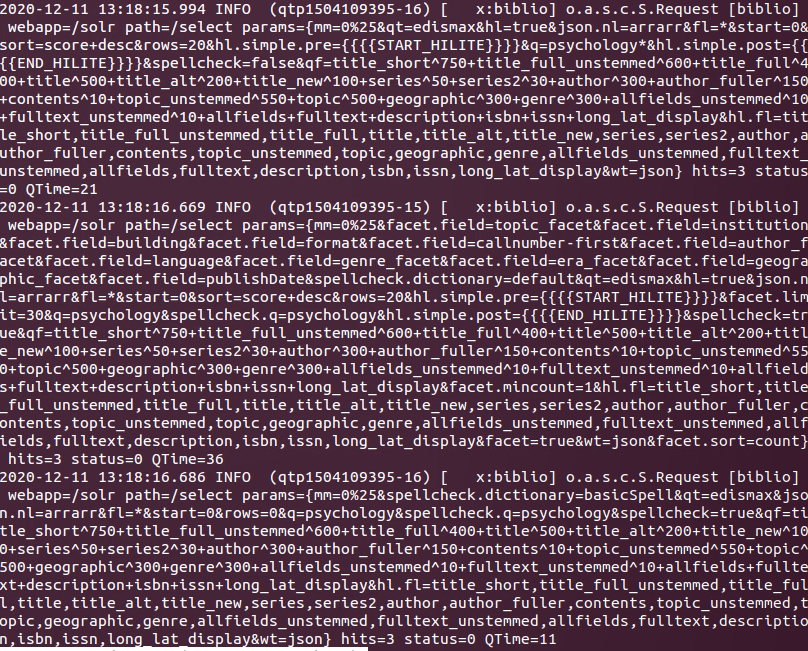
Sieht ganz schön anders aus. Hier wird ersichtlich, wie viel da im Hintergrund bei einer VuFind-Anfrage läuft. Da werden die Felder angegeben, die durchsucht werden und auch das Ranking wird ersichtlich. In diesem Zusammenhang sind dann auch diese paar Zeilen hier interessant:

Das ist nämlich die Gewichtung, wie die Titel angezeigt werden sollen, also die Relevanzsortierung. Da kann man dann feinjustieren, in welcher Reihenfolge die Treffermenge angezeigt wird. Da kann man natürlich sehr lange drüber diskutieren, was die besten Resultate gibt. Es gibt nicht wirklich ein richtig oder falsch, es kommt sehr darauf an, in welchem Fachgebiet man sich bewegt und wie wichtig die entsprechenden Angaben sind.
Daten löschen
Für die nächste Übung - unsere in vorherigen Sitzungen erstellten Daten aus Koha, ArchivesSpace, DSpace und OpenRefine in VuFind zu importieren - müssen wir zuerst den Testdatensatz, mit dem wir die vorherige Übung gemacht haben, löschen.
Hier war meine Kommandozeile erst mal etwas bockig. Obwohl ich den Befehl genau so eingegeben habe wie im gemeinsamen Dokument vorgegeben, hat es mir die Daten nicht aus VuFind gelöscht. Allerdings war ich nicht die einzige mit diesem Problem, weshalb sich auch schnell eine Lösung fand - mal wieder ist es wichtig, die Befehle einzeln einzugeben. Geklappt hat es dann mit diesem Befehl:
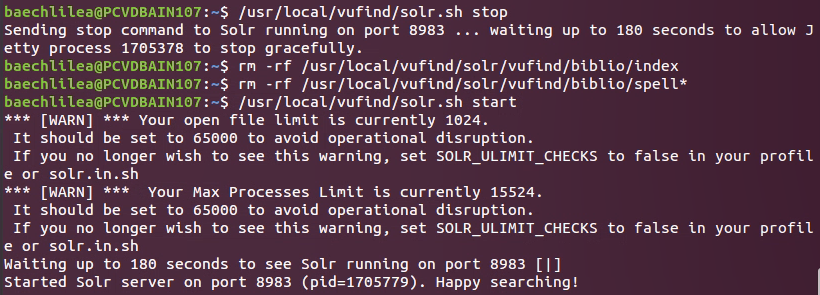
Also zuerst Solr stoppen, dann die Daten löschen und zuletzt Solr wieder starten. Wichtig war v.a., dass diese zwei Zeilen separat aufgeführt worden sind:

Wieso es bei einigen geklappt hat, ohne die Befehle auseinander zu schreiben, während andere nur mit dem obigen Befehl die Daten löschen konnten, ist mir nicht ganz klar, aber wohl auf eine Eigenheit der Linux- oder VuFind-Konfiguration zurückzuführen.
Datenimport
Jetzt sollen also alle unsere zuvor in MARCXML-konvertierten Daten in VuFind importiert werden. Für Koha ging das ohne Probleme, bei den Daten aus ArchivesSpace und DSpace sind etwas schwieriger. Hier gibt die Konsole nämlich diese Meldung aus:
ERROR [SolrUpdate-null-null] (Indexer.java:455) - Failed on single doc with id : null
ERROR [SolrUpdate-null-null] (Indexer.java:465) - Error from server at http://localhost:8983/solr/biblio: Document is missing mandatory uniqueKey field: id
Wo liegt der Fehler? Klar ist, dass diese Daten nicht die ID haben, die VuFind gerne sehen möchte - ohne diese ID ist VuFind nicht in der Lage, die Daten richtig zu identifizeren. Im Schema ist also das Feld id als verpflichtendes Feld festgehalten, worin ein eindeutiger Key enthalten sein muss. Für MARC ist dieses Feld allerdings nicht verpflichtend, weshalb kein MARC-Validator jemals melden würde, dass die Daten nicht valide sind. Also müssen die Daten von ArchivesSpace und DSpace noch händisch mit diesem Feld ergänzt werden. Hat man das gemacht, so sollte jetzt auch der Import in VuFind funktionieren.
Marktüberblick Discovery-Systeme
Aus Platzgründen - dieser Eintrag ist doch schon etwas umfangreicher als geplant - hier nur ganz kurz: Im jährlichen Library Systems Report von Marshall Breeding sind Discovery Systeme natürlich auch vertreten. Hier ist Primo von ExLibris der Markführer bei wissenschaftlichen Bibliotheken und auch Summon (ebenfalls ExLibris) ist gut vertreten. Wahnsinnig viel Konkurrenz gibt es halt (noch?) nicht. Und in der Schweiz ist natürlich das eben gestartete Swisscovery von SLSP erwähnenswert.



