
Exkurs zu OpenRefine
Als Aufgabe mussten wir unsere DOAJ-Daten mit zusätzlichen Informationen aus lobid-gnd anreichern und das entsprechende Template erweitern sowie die so entstandene Datei exportieren. Dieser Eintrag soll von meinen Erfahrungen mit dieser Aufgabe berichten.
Anreicherung mit lobid-gnd
Im lobid-Tutorial werden sehr rudimentäre Beispieldaten verwendet. Wir können hier auf unseren Datensatz mit ca. 1000 Einträgen, den wir bereits für die Library Carpentry Lesson verwendet haben, zurückgreifen.
Wie in der Anleitung beschrieben, starten wir in der Spalte “Authors” den Reconciliation-Prozess. Da müssen wir die Service-URL https://lobid.org/gnd/reconcile angeben, damit die lobd-gnd-Datenbank überhaupt abgerufen werden kann. Lässt man den Prozess dann laufen, bietet sich bei mir dieses Bild:
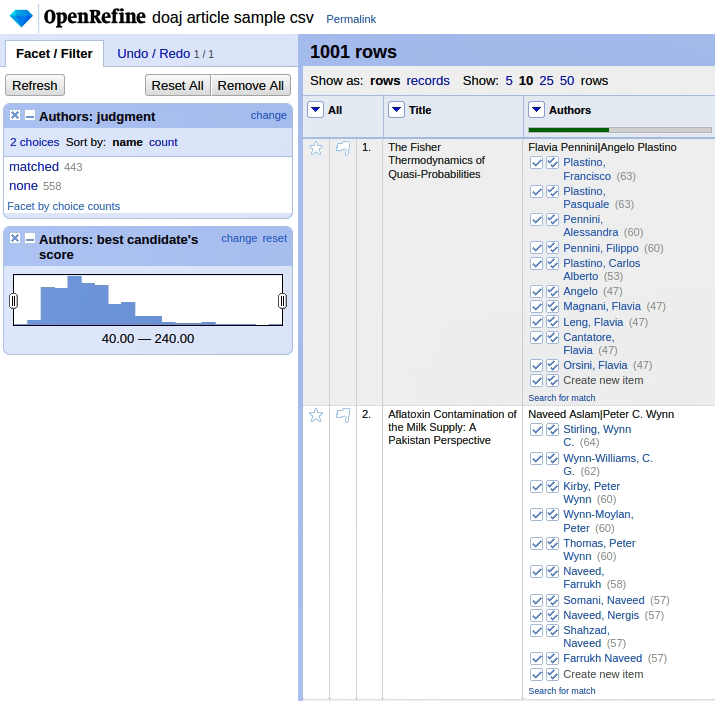
Es hat bei mir für 46% der Einträge Matches gefunden. Der Rest der Daten muss noch reconciliated werden. Ich denke, das ist darauf zurückzuführen, dass es a) entweder keinen entsprechenden Eintrag in der lobid-gnd gibt, oder dass die von mir verwendetetn Daten zum Teil fehlerhaft sein könnten. Ich könnte mich jetzt hier bei jedem einzelnen EIntrag durchklicken und dem auf den Grund gehen, da es sich aber um eine Übung handelt, verzichte ich aus Zeitgründen darauf.
Stattdessen mache ich mit dem Tutorial weiter. Hier kann ich bei den reconciliierten Daten auswählen, welche dass ich “matchen” will. Das sieht dann bspw. so aus:
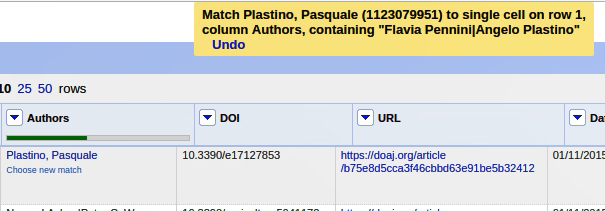
So fahre ich weiter und versuche, immer die von der Form her übereinstimmenden Matches auszuwählen - meistens gibt’s ja mehrere Optionen. Was mir auffällt, ist dass bei diesem Prozess die Werke, die mehrere Autoren haben, dann nur noch einen Autor haben. Vermutlich hätte ich zuerst die Zellen noch mal mit GREL splitten sollen, damit keine Mehrfachnennungen in einer Zelle sind. Für “echte” Daten wäre das natürlich ein absolutes No-Go. Für Übungszwecke drücke ich hier ein Auge zu.
Nachdem die Matches ausgewählt worden sind, kann die Tabelle um die reconciliierten Daten erweitert werden.
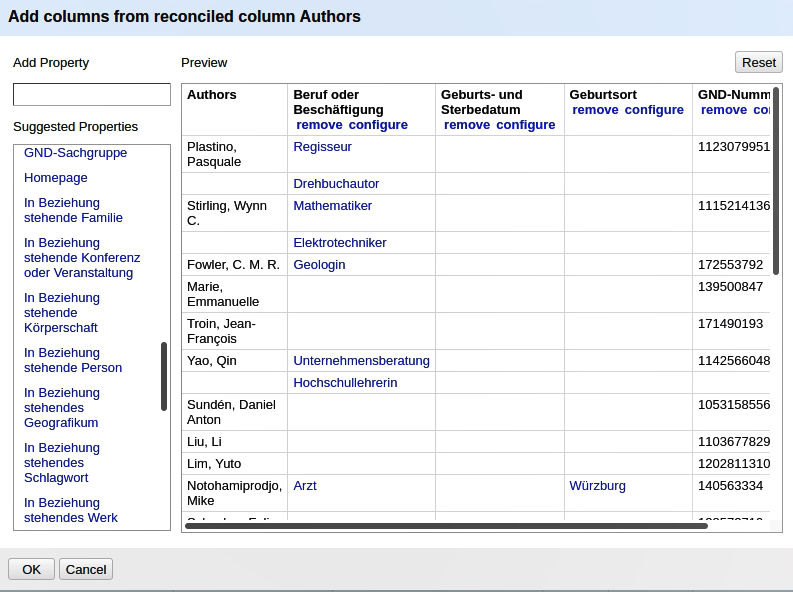
Ich habe mich für Berufsbezeichnung, Geburts- und Sterbedatum, Geburtstort sowie die GND-Nummer entschieden.
Daraufhin kann die Auswahl bestätigt werden, worauf die entsprechenden neuen Spalten zu der bestehenden Tabelle hinzugefügt und mit den GND-Daten befüllt werden.
Templating
Jetzt kommt der zweite Teil dieser Aufgabe, nämlich das Tempate entsprechend zu erweitern und die Daten als XML-Datei zu exportieren.
Ich nehme das bereit in der Stunde erstellte Grundtemplate, das schon einiges mit sich bringt.
Dort haben wir z.B. für das 100er-Feld diese Angabe (als Bild, weil GitHub hier den Code nicht richtig anzeigen will… aus was für Gründen auch immer!)

Das muss aber jetzt noch mit den GND-Daten ergänzt werden. Meine beschränkten Katalogisierungskenntnisse kommen an ihre Grenzen, was gehört wohin? Die Felddokumentation der LoC verschafft Abhilfe - die GND-Nummer kommt ins Subfield 0, Lebensdaten ins Subfield d, nur beim Beruf bin ich etwas unsicher… ist das eventuell Subfield c (“Titles and words associated with a name”)? Und der Geburtsort gehört nicht ins 100er-Feld, sondern ins Feld 370, weiss die Felddokumentation.
Okay, versuchen wir’s mal. Ich ergänze mein 100er Feld-Template und komme auf das:

Mit dem 100er-Feld ist das ja nicht getan, denn das 700er-Feld gibt’s ja auch noch. Leider funktioniert das hier nicht ganz so einfach. Ich bin froh, dass ich die Übung erst nach dem Unterricht machen konnte, denn ich glaube nicht, dass ich das geschafft hätte (oder ich hätte SEHR viele Nerven verloren…) Es braucht nämlich in den leeren Zellen der neuen Spalten (von denen es viele gibt) einen Platzhalter, wie bspw. $. Dann müssen die neuen Spalten zusammengeführt werden. Beide Schritte sind mit OpenRefine ja recht schnell gemacht. Und dann kann das Template ergänzt werden:
forEachIndex(cells['Authors'].value.split('|').slice(1), i, v ,'
<datafield tag="700" ind1="0" ind2=" ">
<subfield code="a">' + v.escape('xml') + '</subfield>'
+ forNonBlank(cells['GND-Nummer'].value.split('|').slice(1)[i].replace('$',''), gnd ,'
<subfield code="0">' + gnd.escape('xml') + '</subfield>', '')
+ forNonBlank(cells['Geburts- und Sterbedatum'].value.split('|').slice(1)[i].replace('$',''), geburt ,'
<subfield code="d">' + geburt.escape('xml') + '</subfield>', '')
+ '</datafield>')
Mein fertiges Template sieht dann so aus:
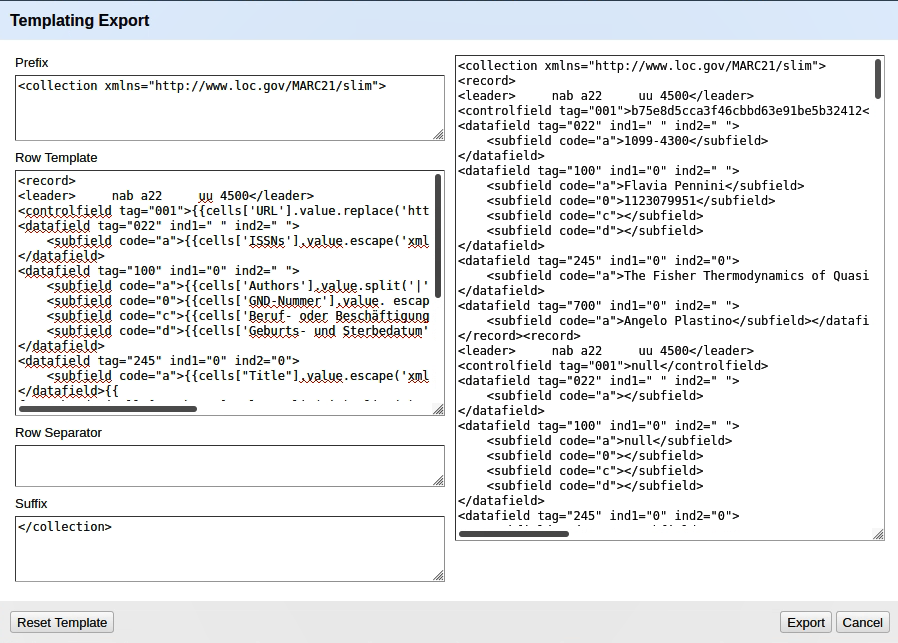
Und exportieren… fertig!
Naja, viele meiner Subfelder sind leer. Was halt auch damit zusammenhängt, dass nicht überall Daten vorhanden waren. Das c- und d-Feld fehlt auch bei den meisten Einträgen, da ist es kein Wunder, dass da dann in der XML-Datei nichts drin steht. Aber trotzdem - die GND-Nummer ist quasi überall da, und das Prinzip habe ich verstanden. Exkurs: done!



