
Lektion VII
Metadaten modellieren und Schnittstellen nutzen: Teil II
Nach einer langen Pause geht es heute endlich weiter mit den Metadaten! Um uns die Zeit zwischen den Lektionen zu verkürzen, hatten wir den Auftrag, noch eine Library Carpentry Lesson zu OpenRefine durchzuarbeiten. Die wichtigsten Erkenntnisse aus dieser Aufgabe möchte ich im Laufe dieses Artikels auch noch kurz zusammenfassen.
OpenRefine
OpenRefine hiess früher mal Google Refine und ganz früher auch mal Freebase Gridworks. Es handelt sich dabei um ein Open-Source-Programm, welches eigentlich herkömmlichen Tabellenverarbeitungsprogrammen ähnelt, von den Möglichkeiten her aber eher an eine Datenbank erinnert. Laut OpenRefine selbst ist das Programm ein mächtiges Werkzeug, um mit “messy data” zu arbeiten. Es dient der Analyse, Bereinigung, Konvertierung und Anreicherung von Daten. So wäre ein möglicher Einsatzbereich z.B. die Bereinigung von MARC-Daten.
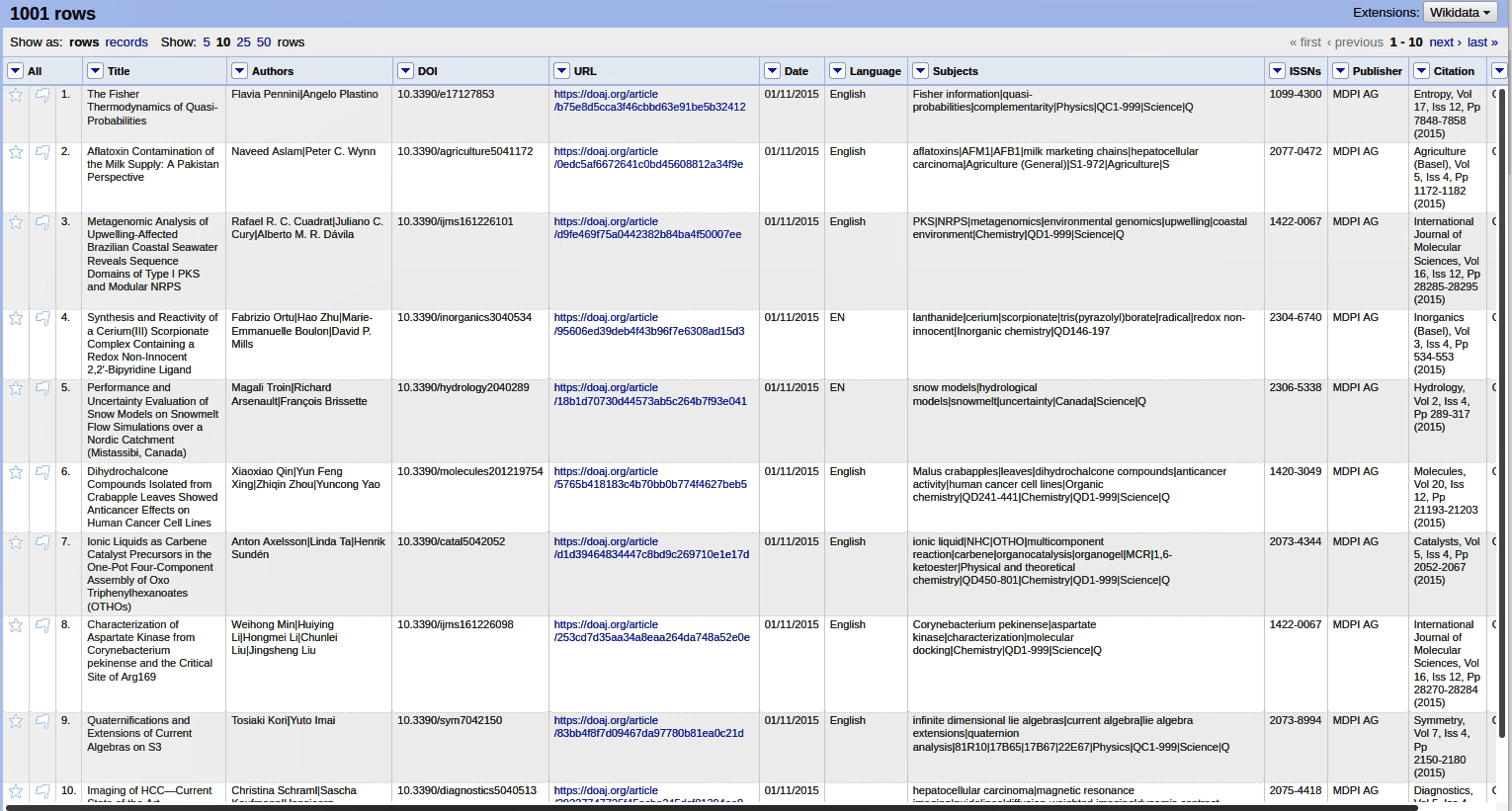
Im Bild ist ein OpenRefine-Projekt abgebildet. Dieses besteht aus Daten, welche tabellenförmig angeordnet sind. Die Beispieldatei dient als Grundlage der Library Carpentry lesson und wurde noch nicht bearbeitet. Diese Tabellen können gefiltert und transformiert werden und natürlich können auch neue Spalten oder Zeilen hinzugefügt werden. Um Daten zu transformieren, wird die General Refine Expression Language (oder kurz: GREL) verwendet. Mehr dazu dann im nächsten Unterkapitel zur Library Carpentry Lesson.
Wichtig im Zusammenhang mit OpenRefine ist der Begriff der “Reconciliation”, also dem Abgleich mit Normdaten (z.B. Wikidata, GND oder VIAF).
Library Carpentry Lesson
Wie schon erwähnt mussten wir als Vorbereitung auf heute eine Library Carpentry Lesson zu OpenRefine durcharbeiten. In dieser lernt man zuerst mal die einfachsten Funktionen von OpenRefine kennen, also z.B. wie Daten importiert werden können, wie die Daten organisiert sind, wie man diese filtern kann etc.
Spannend wird es dann, wenn es um Transformationen geht. Hier kommt nämlich GREL dazu. Mit GREL können Daten transformiert werden, also z.B. eine einzelne Spalte in mehrere Spalten zerlegen (hilfreich bspw. für Bücher mit mehreren Verfasserangaben), Daten können standardisiert werden (bspw. Datumsangaben), oder einzelne Strings können aus längeren Sequenzen herausgefiltert werden (bspw. eine DOI).
Als Beispiel: Um die Autorennamen, welche mit | voneinander getrennt sind, zu trennen, kann die split-Funktion verwendet werden. Der Befehl sähe dann so aus:
value.split("|")
Es empfiehlt sich also bei den Daten, keine Zeichen wie Kommas, Punkte, Semikolons oder Bindestriche zu verwenden, da sonst evtl. Werte getrennt werden könnten, die Zusammengehören (z.B. der Name “Müller-Muster” würde mit einem value.split("-") in zwei verschiedene Namen getrennt werden).
Weiteres zu OpenRefine und GREL ist in der Library Carpentry Lesson zu lesen.
Templating
Ähnlich, wie wir es auch schon bei den XSLT-Crosswalks gemacht haben, können wir auch bei OpenRefine (CSV) Daten zu MARCXML konvertieren. Dazu bietet OpenRefine eine ziemlich praktische Funktion namens Templating Exporter. Anders als bei den Crosswalks können hier die Daten nämlich direkt bearbeitet werden. Wie wir das gemacht haben, will ich im Folgenden kurz schildern.
Als Basis dienten die von der Library Carpentry Lesson bereitgestellten Daten. Ich habe diese nochmals in ein neues Projekt geladen, um sicher zu gehen, dass dann alles klappen wird. Dann kann man oben rechts über den Menupunkt “Export” auf “Templating” die Templatingvorlage aufmachen. Diese ist schon ebfüllt mit Angaben, die wir aber für unseren Zweck herausgelöscht haben.
Im Prefix und Suffix kann man dann die nötigen Anpassungen machen - wir haben es z.B. adefiniert, dass es sich um MARC21-Daten handeln soll. Wichtig ist, dass man dann im Suffix den Tag, den man im Prefix verwendet hat, auch wieder schliesst.
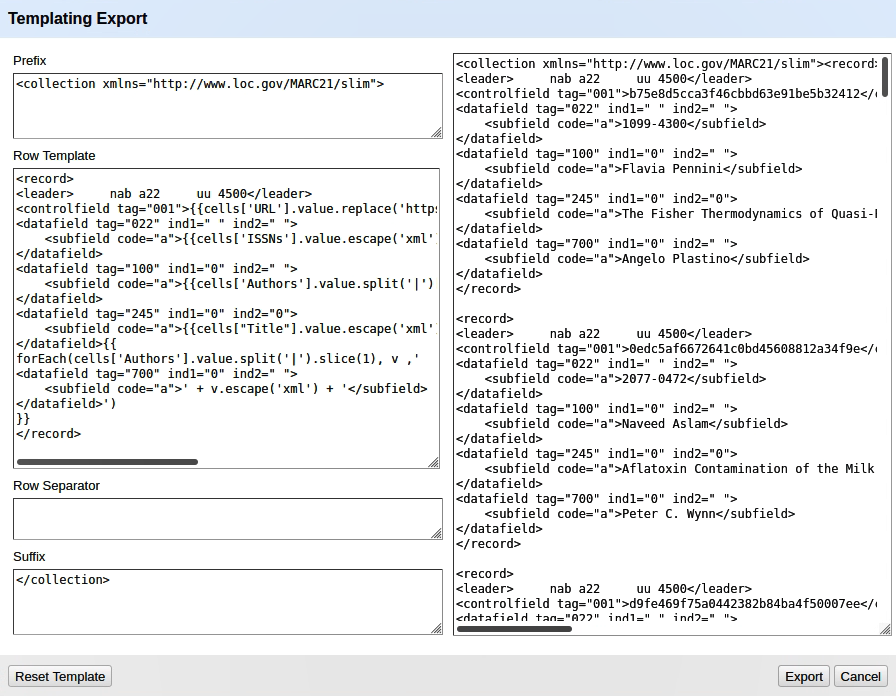
Das Row Template ist dann der Ort, wo wir am meisten Gestaltungsmöglichkeiten haben. Wir können hier z.B. definieren, welche Spalte welche Werte enthalten soll, wie diese umgeformt werden sollen oder in welches MARC-Feld diese Werte gehören. Dazu verwenden wir GREL. Praktisch ist, dass jede Änderung im Template sofort als Vorschau angezeigt wird, d.h. man weiss immer, ob das, was man gerade gemacht hat, auch funktioniert hat. Da muss man nicht zuerst die Datei exportieren und das manuell überprüfen.
Ein ausgefülltes Template sieht dann so aus:
Fazit
Ich habe während dieser Sitzung immer an meine eigene Bibliothek gedacht und denke, so was mal zu verwenden, um Daten zu bereinigen, wäre schon ziemlich praktisch. Mir fallen immer wieder Fehler auf, die entweder intern oder extern durch unseren Datenlieferanten entstehen - unsere Datenbank ist also schon ein bisschen “messy”. Und gerade in diesem Jahr haben wir unsere Medienpräsentation überarbeitet, weshalb auch viele Kataloganpassungen fällig geworden sind. Hier wäre ein Tool wie OpenRefine schon sehr nützlich gewesen.
Leider sind wir in dieser Lektion nicht so weit gekommen, wie erhofft. Das lag sicherlich auch etwas an den müden Gemütern - ich war da keine Ausnahme, die Woche war streng. Auf jeden Fall werden wir das Thema Metadaten beim nächsten Mal nochmals aufnehmen.



