
Lektion VI
Metadaten modellieren und Schnittstellen nutzen: Teil I
In diesem ersten Teil zu Metadaten und Schnittstellen schauen wir uns zuerst das Harvsten an und dann XSLT Crosswalks. In der nächsten Sitzung geht es dann an die Metadatenmodellierung.
Wir haben in diesem Kurs bereits einige Schnittstellen kennengelernt. Die Z39.50-Schnittstelle ist im Bibliotheksbereich gut etabliert, aber auch schon etwas in die Jahre gekommen. Sie wird deshalb oftmals von SRU (Search/Retrieve via URL) ergänzt. Diese beiden Schnittstellen werden besonders für den gezielten Datenabruf verwendet. Da verhält sich die ebenfalls bekannte Schnittstelle OAI-PMH etwas anders, denn diese wird vor allem für grosse Datenmengen verwendet, welche so abgezogen werden können.
Harvesting
Harvesting kommt aus dem Englischen und bedeutet so viel wie “ernten”. Man kann sich also vorstellen, dass wir mit einem Mähdrescher über unsere Daten fahren und diese wie Weizen einsammeln. Genau so (einfach ein bisschen anders) funktioniert nämlich ein Metadatenharvester.
Wir verwenden im Kurs VuFindHarvest. Ursprünglich war metha eingeplant, aber dieses Tool erwies sich nicht als praktikabel für unseren Kurs. VuFindHarvest wird dazu verwendet, um via OAI-PMH Metadaten von einem oder mehreren Repositorien zu harvesten.
VuFind Harvest musste wieder über die Konsole installiert werden, was alles ohne Probleme möglich war. Dann wurden die Beispieldaten, die wir für Koha und ArchivesSpace erstellt haben sowie die von DSpace bereitgestellten Daten “geharvestet”. Das ging mit folgenden Befehlen:
cd ~/vufindharvest-4.0.1: wechselt in das VuFindHarvest-Verzeichnis
php bin/harvest_oai.php --url=http://bibliothek.meine-schule.org/cgi-bin/koha/oai.pl --metadataPrefix=marcxml koha: lädt die Daten von Koha im Format marcxml herunter und speichert sie im neuen Ordner koha.
Für ArchivesSpace musste dann nur die URL auf http://localhost:8082, das Datenformat auf oai_ead geändert und der neue Ordner archivesspace erstellt werden.
DSpace verlangt da noch einen weiteren Schritt. Es muss nämlich das richtige Datenset mit dem --set=-Befehl ausgewählt werden - von den Dozierenden wurde uns das Set com_10673_1 vorgegeben. Der vollständige Befehl lautet also dann:
php bin/harvest_oai.php --url=http://demo.dspace.org/oai/request --set=com_10673_1 --metadataPrefix=oai_dc dspace
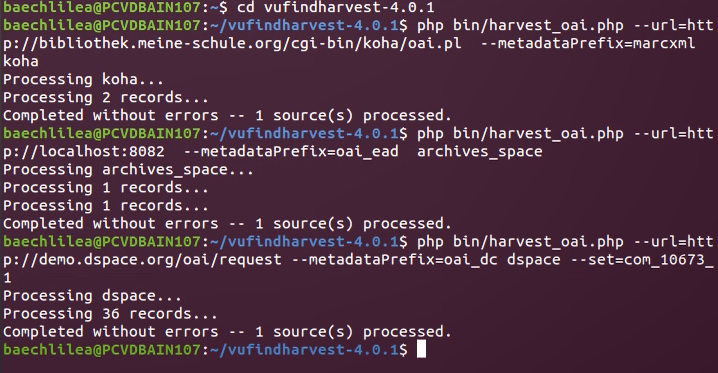
So hat das dann alles wunderbar geklappt.
XSLT Crosswalks mit MarcEdit
XSLT steht für XSL Transformation und ist damit Teil der Extensible Stylesheet Language (XSL). Es handelt sich dabei um eine Programmiersprache zur Transformation von XML-Dokumenten, die 1999 als Empfehlung von W3C veröffentlicht worden ist.
“Crosswalks” (zu Deutsch: Zebrastreifen… wieder so eine Metapher) bezeichnet die Konvertierung von einem Metadatenstandard (z.B. EAD) zu einem anderen (z.B. MARC21). Im Crosswalk sind Regeln fürs Mapping vorhanden, also wie welche Elemente und Werte zugeordnet oder verändert werden müssen, damit die Daten nach der Konvertierung integer sind. Das passiert im Idealfall verlustfrei, was aber in der Praxis oft nicht möglich ist - meist gibt es keine 1:1 Zuordnung. (Wenn es so einfach wäre, bräuchte es ja auch nicht so viele verschiedene Metadatenstandards).
Wir verwenden im Kurs das Programm MarcEdit. Zugegebenermassen ist das nicht gerade das benutzerfreundlichste Programm, das ich jemals benutzen durfte. Aber es ist ein kostenloses Programm, das auch relativ weit verbreitet ist. Da es für eine Windows-Umgebung entworfen wurde, haben sich noch ein paar Stolpersteine in die Linuxversion eingeschlichen. So muss z.B. in den Einstellungen für die einzelnen Konvertierungsvarianten (also z.B. EAD zu MARC) noch ein \ mit einem / ersetz werden. Das muss man auch zuerst wissen…
Wir mussten dann die in der ersten Übung heruntergeladenen Daten von ArchivesSpace und DSpace zu MARC21-Daten umwandeln (die Daten von Koha sind ja schon in MARC21 vorhanden). Dazu mussten wir die jeweiligen Dateien in MarcEdit importieren und diese dann als MARCXML (= MARC21) exportieren. Für DSpace war das alles unproblematisch, da die Metadaten von DSpace in Dublin Core vorliegen. ArchivesSpace verwendet bekanntlichermassen das Datenaustauschformat EAD. Hier sind sozusagen zwei Konvertierungsschritte nötig, um am Schluss MARC21-Daten zu erhalten.
Werden die Daten aus ArchivesSpace von EAD zu MARC konvertiert, sieht das erstmal so aus.
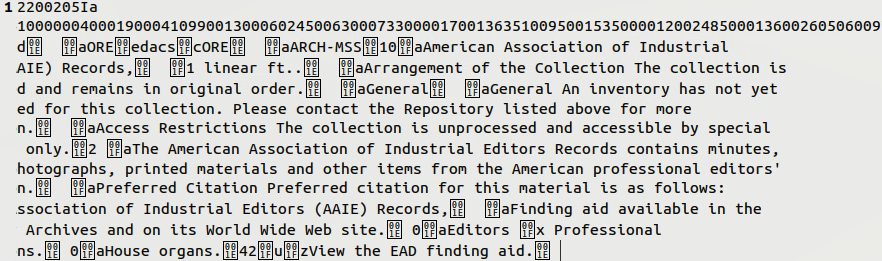
Das ist nicht gerade das, was wir wollen. Zuerst war ich da unsicher, ob ich etwas falsch gemacht habe. Nachdem ich es dann noch fünfmal probiert habe und jeweils ein bisschen mit den Parametern herumgespielt habe, kam aber nichts besseres heraus. Zur Kontrolle habe ich das konvertierte File in MarcEdit geöffnet, dort sah alles ganz okay aus. Also vielleicht doch nicht so falsch?
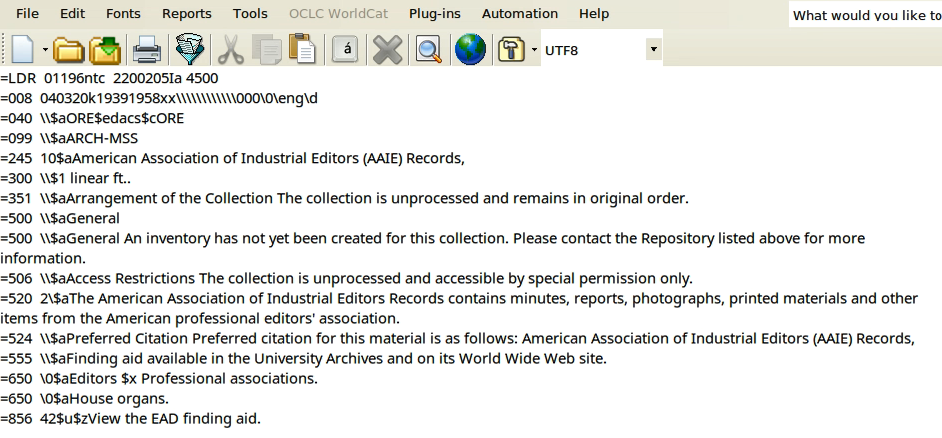
Was war da falsch? Der grosse Aha!-Moment erfolgte dann erst in der Besprechung der Aufgabe im Plenum: Die Daten werden von EAD nicht direkt nach MARCXML konvertiert. Dazu ist, wie oben bereits erwähnt, ein zweiter Konvertierungsschritt von MARC zu MARCXML notwendig. Und siehe da: Die Daten sehen einigermassen so aus, wie sie sollten. Was noch nicht stimmt, ist die schöne Darstellung, aber so stimmen auf jeden Fall die einzelnen Felder.

Ich bin zufrieden, hoffe aber, dass ich MarcEdit nicht so schnell wieder benutzen muss.



