
Lektion II
Die zweite Lerneinheit beginnt mit einigen Kommentaren und Fragen zu den Lerntagebüchern. Dann kommt mit dem Teil zu der Versionskontrolle mit Git der Teil, der eigentlich schon das letzte Mal drankommen sollte – aus zeitlichen Gründen hat es dann nicht mehr gereicht.
Versionskontrolle mit Git
Git ist eine vom Linux-Entwickler Linus Torvalds eingeführte Software zur Versionskontrolle von Dateien, die lokal auf dem Computer läuft. Sie eignet sich besonders gut, um Quellcode, HTML-/XML-Dateien oder auch Markdown mit anderen Personen zu teilen und die Änderungen nachvollziehbar zu machen. Das Repository GitHub basiert auf Git, welches über einen Webserver läuft.
Als Übung haben wir dann Git gerade dazu gebraucht, um das offizielle Dokument via «fork», «clone», «commit» und «pull request» mit dem Link zum eigenen Lerntagebuch zu ergänzen. Das hat mit der Anleitung ziemlich gut geklappt… ausser, dass ich dann beim zweitletzten Schritt nicht weitergescrollt habe und das Gefühl hatte, schon fertig zu sein. Auf GitHub den Pull Request zu erstellen, kam mir dann erst in den Sinn, als der Dozent es erwähnt hat – aber am Ende habe ich es auch geschafft.
Funktion und Aufbau von Bibliothekssystemen I
Heute haben wir den ersten Teil dieses grossen, wichtigen Themas. Mit einem kurzen Input zu Metadatenstandards in Bibliotheken und einem ersten Bibliothekssystem, das wir näher kennen lernen, starten wir heute – in der nächsten Sitzung geht’s dann weiter.
Metadatenstandards in Bibliotheken (MARC21)
Mit MARC21 schauen wir uns den wohl einen der wichtigsten Metadatenstandard in der Bibliothekswelt an. Gegründet wurde der Standard – wie so viele Standards! – von der Library of Congress, und zwar vor mehr als 20 Jahren, im Jahr 1999. Die Daten werden grundsätzlich binär in einem eigenen Binärformat (´.mrc´) abgespeichert, es gibt aber auch eine XML-Option, was das Ganze menschenlesbar macht. Da momentan der Trend richtung Linked Data geht und MARC21 diesen Anforderungen nicht mehr genügt, wird wohl bald BIBFRAME MARC21 ablösen, da BIBFRAME auf RDF basiert und damit auch Ontologien unterstützt.
Leider konnten wir nur ganz kurz auf die Metadaten bzw. MARC21 eingehen. Wir haben das zwar im Laufe des Studiums schon mal behandelt und immer wieder mal am Rande angesprochen, aber das liegt alles schon seeeeeeehr lange zurück – die kurze Auffrischung hat aber sicher gutgetan. Ich fände es spannend, wenn wir aber noch auf BIBFRAME eingehen würden, wenn wir Zeit dazu haben – vor allem, wenn da die Zukunft liegt.
(UPDATE: Wir hatten in der letzten Lektion noch kurz Zeit, um auf BIBFRAME einzuegehen. Mehr dazu also hier.)
Koha
Und schon lernen wir mit Koha unser erstes Bibliothekssystem kennen!
Zum System
Koha ist ein Open Source Programm, welches weltweit in vielen verschiedenen Arten von Bibliotheken eingesetzt wird. Es ist ein webbasiertes integriertes Bibliothekssystem, welches als Datenbanksprache SQL verwendet. Neben der Verwaltung normaler Bibliotheksabläufen (wie Ausleihen, Bestandesverwaltung, Periodika-Verwaltungen, etc.) werden auch andere Funktionen wie Markierungen, Kommentare und auch RSS-Feeds unterstützt, weiss Wikipedia. Es wird laufend weiterentwickelt, wie die Statistik bei Open Hub zeigt. Bei Open Source Projekten sagt das sehr viel über die Gesundheit eines Systems aus, wenn es regelmässig und von verschiedenen Personen aktualisiert wird.
Übrigens: Der Name leitet sich laut Wikipedia vom maorischen Wort «Koha» ab, was ein Geschenk ist, bei dem aber ein Gegengeschenk erwartet wird. Eigentlich treffend für ein Open Source Projekt, bei dem der Code immer durch weitere Updates von vielen verschiedenen Leuten weiterentwickelt und damit sozusagen «weitergeschenkt» wird…
Installieren & Konfigurieren – ein Exkurs in Copy/Paste
In unserem gemeinsamen Dokument hat uns unser Dozent schon eine wunderbare Anleitung zur Installation von Koha (Version 20.05) vorbereitet. Diese orientiert sich an der offiziellen Installationsanleitung, ist aber um einige Schritte kürzer – wir brauchen für den Unterricht ja auch nicht alle Funktionalitäten von Koha.
Das Installieren hat bei mir ziemlich gut geklappt. Ich habe zwar versucht, alles zu verstehen, das ich da ge-copied und ge-pasted habe, es wäre aber gelogen, wenn ich sagen würde, ich hätte das auch auf eigene Faust hingekriegt.
Gestolpert bin ich dann aber beim Einloggen. Da erst im Tutorial von Stephan Tetzel darauf hingewiesen wird, dass der Benutzername immer mit ´koha_benutzername´ beginnt, hatte ich zuerst schon ziemliche Panik, dass das alles nicht geklappt hat. Auf meinem Linux-Rechner habe ich auch keine Dateien zu Koha gefunden – da half dann der Hinweis auf der Login-Seite, dass der Benutzername im koha-conf.xml-File zu finden sei, auch nicht wirklich viel. Im Tutorial von Stephan Tetzel wird unter dem Abschnitt «Installation» geschrieben, dass ein LXD-Container verwendet wird – ich nehme an, wir machen das auch. Wenn ich das richtig verstanden habe, dann sind Linuxcontainer eine Art virtuelle Maschine – nur halt anders, speziell auf Webanwendungen ausgerichtet und anscheinend auch schneller.
Bis zur nächsten Sitzung sollten wir dann noch ein Koha-Tutorial von Stephan Tetzel durchführen, insbesondere die Kapitel 1-3. Nach anfänglichen Schwierigkeiten, die v.a. mit dem Horizon Client zusammenhingen - es hat mir trotz VPN immer die Fehlermeldung, dass der Hostname nicht aufgelöst werden kann, angezeigt (woraufhin ich meinen Computer einige Stunden zur Seite gestellt habe, und dann ging es mit den genau gleichen Einstellungen dann trotzdem!) - konnte ich mit dem Tutorial beginnen.
Ich habe mich bezüglich Beispieldaten und Vorlagen an die von Stephan Tetzel bereits ausgewählten Optionen gehalten. Nämlich sind das
- Bibliographisches Standard-Framework für MARC21
- „FA“, ein MARC21-Framework (Erfassungsmaske) für Schnellaufnahmen und Fernleihtitel
- Beispiele für die Auswahllisten der verschiedenen normierten Werte (Verloren, Beschädigt, Sammlung, Standort etc.) …
- Nützliche Benutzerattribute
Dann wird man durch das Einrichten eines ersten Benutzertyps (Mitarbeiter), eines Administratorkontos (meins), eines ersten Medientyps (Bücher) und schlussendlich auch zu den Ausleihkonditionen geführt. Das ist alles ziemlich straightforward. Damit ein Eindruck entsteht, wie das Ganze aussehen kann, füge ich hier einen Screenshot ein, wie ich meine Ausleihkonditionen definiert habe. Die sind ziemlich an die KBL, wo ich arbeite, angelehnt - so kann ich das dann auch besser mit dem mir schon bekannten System vergleichen, was Möglichkeiten & Funktionalitäten von Koha angeht.
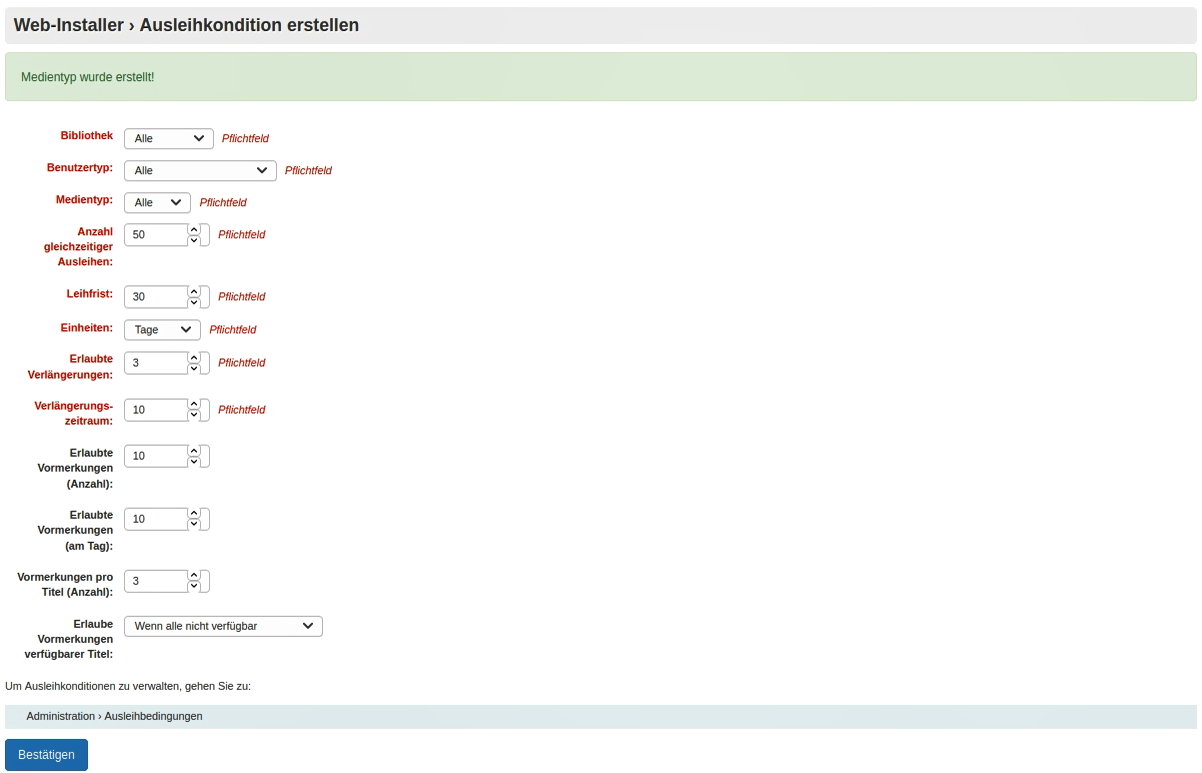
Weiter geht’s dann mit den allgemeinen Einstellungen für die Bibliothek. So sind zuerst Adressdaten anzugeben. Und dann können zum ersten Medientyp Buch auch noch weitere hinzugefügt werden (in meinem Fall einfachheitshalber DVDs und CDs). Auch Nutzertypen können sehr einfach angelegt werden. Ich habe mal Erwachsene und Kinder als Nutzertypn angelegt. Das sieht dann erst mal so aus:
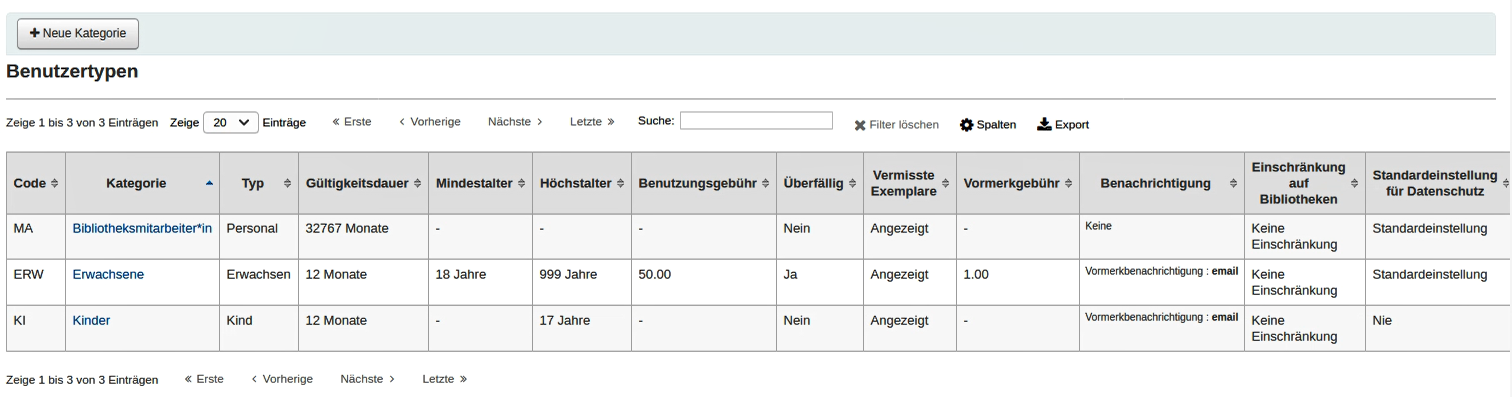
Dann folgte ein kurzer Exkurs in die vielen möglichen Einstellungen und Spezifikationen im Rahmen der Systemparameter. Ich war von der Auswahl beinahe erschlagen! Da habe ich mich auch durchs Tutorial durchgearbeitet. Aus Zeitgründen hat es mir dann nicht mehr gereicht, die weiteren Kapitel des Tutorials anzuschauen. Aber das werde ich sicher noch nachholen, bis jetzt gefällt mir Koha nämlich sehr.



